Before I started this course I have a limited knowledge and experience about Linux and using the command line interface. After starting this semester, I have definitely increased my understanding of using both the GUI and CLI using the VM ware software.
With the building of my repositories, and creating them through the different software applications such as Drupal, Eprints, Dspace, Omeka and the associated plugins such as Harvester, and Jhove, they have been very valuable in giving me an overview of how the different applications are able to organize data for the data collections.
In addition, this process of building through using different software has also given me insight into how a manager would have to look at the budget allocated for their organization, and how to choose the best software applications to implement their collection and the different criteria needed to make the proper assessments.
I found the process re-emphasizing the importance of how to implement a controlled vocabulary and using the proper taxonomy when creating and organizing the repositories.
This course has given me a chance to review and determine the strengths and weaknesses of the different software applications and what would be the best organizational environment for the implementation of the repository software based on the previously mentioned criteria, of budget, features, ease of installation, ability to handle large data collections.
Wednesday, December 8, 2010
Friday, December 3, 2010
Unit: 12
In installing the software for the Virtual Machines on windows 7 I really didn't have much difficulty in accomplishing this. Through using the VM for the assignments I found a deeper understanding in the differences in using a CLI versus a GUI.
I would prefer to use a Virtual Machine over a preconfigured server such as Ubuntu as I am feeling comfortable with the CLI in the VM. The most issue with using the command line is that your syntax has to always be exactly correct and there is no room for errors. Of course the visual GUI is more comfortable and faster.
Although, having a pre-configured machine, where as all one had to do is to add the digital collection would be much easier and less complicated. I can see however, if I was in an IT position, in a location where a windows installation previously existed it would be a definite advantage in having a working knowledge of Virtual Machines.
All of this of course depends on the bandwidth being used in the application and how much traffic one is expecting for the repositories in question, in which case I would recommend using a dedicated Linux server.
From a cost perspective I would all in all have to go with the Linux installation to host the repository.
In conclsion, I think that it was very valuable to learn how to build a repository from scratch and will come in handy in my future studies.
I would prefer to use a Virtual Machine over a preconfigured server such as Ubuntu as I am feeling comfortable with the CLI in the VM. The most issue with using the command line is that your syntax has to always be exactly correct and there is no room for errors. Of course the visual GUI is more comfortable and faster.
Although, having a pre-configured machine, where as all one had to do is to add the digital collection would be much easier and less complicated. I can see however, if I was in an IT position, in a location where a windows installation previously existed it would be a definite advantage in having a working knowledge of Virtual Machines.
All of this of course depends on the bandwidth being used in the application and how much traffic one is expecting for the repositories in question, in which case I would recommend using a dedicated Linux server.
From a cost perspective I would all in all have to go with the Linux installation to host the repository.
In conclsion, I think that it was very valuable to learn how to build a repository from scratch and will come in handy in my future studies.
Unit: 11
The Eprints website provides a global solution for repositories, and is used in over 299 archives worldwide. This alone says a lot for it and gives it a high rate of success as a solution that can handle a large number of document requests. It does seem however that one would have to give a lot of detailed thought, as in order to enter the data into the collection you have to go through many steps which seem redundant. Also, it seems that in browsing, you are given the subject headings and then having to choose the controlled vocabulary as well.
My opinion is that EPrints is made for professional institutions, and here is where the strength lies as stated on the homepage, as it can address a large bandwidth of users and document downloads. I found Omeka.org to be a nicely designed website which provided the information in a simplistic, clear fashion which made me want to download and install it. The help documentation was very clear and concise as well.
In my visit to DSpace.org I like the overall design of the website and layout of the menu. It seemed that DSpace allows a lot of customization for the software itself. There is support for the customization; however, the support seems that it could be clearer and simpler in elucidation of the steps. It seems that one could easily get overwhelmed with all of the available customizations in configuring DSpace.
My overall favorite would have to be the Drupal website and software. When you first browse to the website one finds an immediate sense of the Drupal community. The website provides excellent documentation regarding the installation and customization of the software. In addition, it is constantly being upgraded and updated, being an open source project, with over 725,443 people in 228 countries using Drupal, it would be my definite choice for implementing a repository.
Some of the success stories for Drupal include “The White House”, which in itself is very impressive and speaks highly about Drupal capabilities and security. With over 7,269 modules for support, Drupal is set up to handle even the most strenuous requirements of webmasters creativity.
I found that the Harvester website was of course as expected, very technical in nature geared towards the seasoned IT professional. It was very clear and concise and straight forward, in its organization of the support documentation.
Harvester seems to me to be one of the most important tools in the harvesting of information across multiple repositories. In addition, I noticed a myriad of additional tools that can be used in conjunction with Harvester. All in all, I look forwards to further working with Harvester.
The Jhove website is also directed towards the IT professional, with a large amount of experience with integrating plugins, into existing websites. This particular plugin seems to be directed towards be able to automate the task of identifying the format of the digital media in a collection for the purpose of very large collections, where decisions regarding policy, storage, preservation, and processing are the key elements. It provides a CLI for accessing the API, and also a swing based on GUI for invoking Jhove.
My opinion is that EPrints is made for professional institutions, and here is where the strength lies as stated on the homepage, as it can address a large bandwidth of users and document downloads. I found Omeka.org to be a nicely designed website which provided the information in a simplistic, clear fashion which made me want to download and install it. The help documentation was very clear and concise as well.
In my visit to DSpace.org I like the overall design of the website and layout of the menu. It seemed that DSpace allows a lot of customization for the software itself. There is support for the customization; however, the support seems that it could be clearer and simpler in elucidation of the steps. It seems that one could easily get overwhelmed with all of the available customizations in configuring DSpace.
My overall favorite would have to be the Drupal website and software. When you first browse to the website one finds an immediate sense of the Drupal community. The website provides excellent documentation regarding the installation and customization of the software. In addition, it is constantly being upgraded and updated, being an open source project, with over 725,443 people in 228 countries using Drupal, it would be my definite choice for implementing a repository.
Some of the success stories for Drupal include “The White House”, which in itself is very impressive and speaks highly about Drupal capabilities and security. With over 7,269 modules for support, Drupal is set up to handle even the most strenuous requirements of webmasters creativity.
I found that the Harvester website was of course as expected, very technical in nature geared towards the seasoned IT professional. It was very clear and concise and straight forward, in its organization of the support documentation.
Harvester seems to me to be one of the most important tools in the harvesting of information across multiple repositories. In addition, I noticed a myriad of additional tools that can be used in conjunction with Harvester. All in all, I look forwards to further working with Harvester.
The Jhove website is also directed towards the IT professional, with a large amount of experience with integrating plugins, into existing websites. This particular plugin seems to be directed towards be able to automate the task of identifying the format of the digital media in a collection for the purpose of very large collections, where decisions regarding policy, storage, preservation, and processing are the key elements. It provides a CLI for accessing the API, and also a swing based on GUI for invoking Jhove.
Wednesday, December 1, 2010
Unit 10: Useful Providers
I found the listing of service providers at the link http://www.openarchives.org/Register/Browse Sites .
First, Humboldt University of Berlin had 8 different contributing sources. I feel that this was a good source overall, as it had articles which related to my digital collection. Based on the fact that this source was not directly a sports source I think they did a good job of at least having relevant collections. I enjoyed the relative ease and simplicity of using their search repository.
Secondly, the Internet Archive OAI Repository is a fantastic collection utilizing at least 11 major contributors including the “Library of Congress” to “National Science Foundation” just to name a few.I like the setup of the search page which is very simple with access to over 150 billion pages of information. I would have to say this was one of my favorite websites and I have bookmarked it as its layout is simple but very concise and clear.
Thirdly, I found Diva.org and it was a quick and easy search , however, the results and meta-data were not very relevant to the search. It was difficult to find information regarding Arabian soccer championships on this website, so although easy to use, it was lacking the detailed meta-information desired.
Even though this website indexed information from a number of sources, the sources, were lacking relevance.
First, Humboldt University of Berlin had 8 different contributing sources. I feel that this was a good source overall, as it had articles which related to my digital collection. Based on the fact that this source was not directly a sports source I think they did a good job of at least having relevant collections. I enjoyed the relative ease and simplicity of using their search repository.
Secondly, the Internet Archive OAI Repository is a fantastic collection utilizing at least 11 major contributors including the “Library of Congress” to “National Science Foundation” just to name a few.I like the setup of the search page which is very simple with access to over 150 billion pages of information. I would have to say this was one of my favorite websites and I have bookmarked it as its layout is simple but very concise and clear.
Thirdly, I found Diva.org and it was a quick and easy search , however, the results and meta-data were not very relevant to the search. It was difficult to find information regarding Arabian soccer championships on this website, so although easy to use, it was lacking the detailed meta-information desired.
Even though this website indexed information from a number of sources, the sources, were lacking relevance.
Unit 9: Cataloging
I would have to say that throughout this entire process of utilizing the different systems of “content management”, I have found it to be a definite challenge in that it is very time consuming to learn the different systems of cataloging, and implementation of data collections.
In addressing the consistency aspect, I feel that it was not difficult to maintain the consistency across the different content management systems such as Drupal, Eprintss, Dspace . In adding the catalog items, I found that by being methodical, and slow with clarity of focus, that this aided me greatly so that it was not as difficult a challenge as I anticipated it would be.
If a company had a need for the services of a good cataloging system and they did not have anyone in house trained to implement the system and would have to purchase this service, it certainly would be an expensive proposition for any company.
I feel that the cost depends on the need of the company as if the company is in a business that utilizes the “data collection”, that is constantly being updated, and this has an important impact on how the business makes their money, than it might be better to hire staff that is already trained in cataloging using the most efficient systems to return precise results for their customers.
In addressing the consistency aspect, I feel that it was not difficult to maintain the consistency across the different content management systems such as Drupal, Eprintss, Dspace . In adding the catalog items, I found that by being methodical, and slow with clarity of focus, that this aided me greatly so that it was not as difficult a challenge as I anticipated it would be.
If a company had a need for the services of a good cataloging system and they did not have anyone in house trained to implement the system and would have to purchase this service, it certainly would be an expensive proposition for any company.
I feel that the cost depends on the need of the company as if the company is in a business that utilizes the “data collection”, that is constantly being updated, and this has an important impact on how the business makes their money, than it might be better to hire staff that is already trained in cataloging using the most efficient systems to return precise results for their customers.
Tuesday, October 19, 2010
EPrints
In comparing the installation process of Drupal and Dspace, with EPrints, I would have to say most definitely it was easier than Drupal and Dspace, with the exception of the inferred logic of the installation instructions. However, other than that, I would have to say that it was a quicker installation using the apt method, and I would have to recommend to anyone else to use this versus the manual method.
Friday, October 15, 2010
Unit7: Creating Database
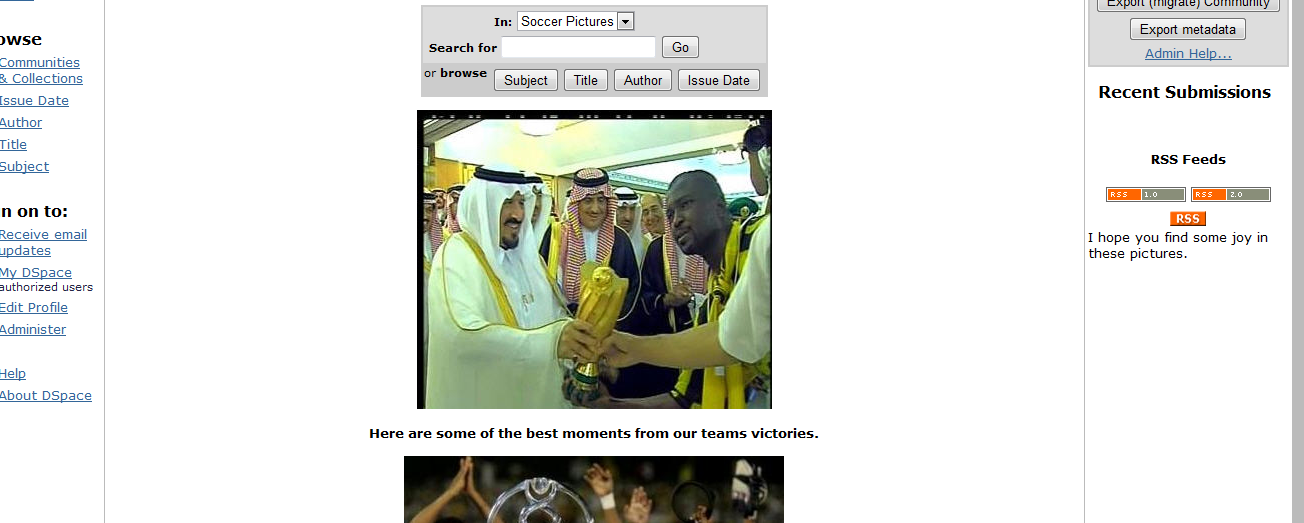
A future area which I would like to explore would be to create a possible database page in which the person enters their name and interests into the fields, and then it is saved into the database, and finally displayed on another page if it is possible with Dspace.
Subscribe to:
Comments (Atom)